Analysis of Developmental Language Data Using Multiple Regression¶
Linear Relationships¶
One of the most basic things a researcher is interested in is seeing whether there is any relationship between variables. Here, we will look at data from Nettle (1998).

Data¶
Nettle recorded:
- the number of languages
- the area (in km2)
- the population
- the mean growing season (MGS, in months)
- the number of weather stations measuring MGS
- the standard deviation of the measurements of MGS from the different weather stations in each country.
from os import chdir as cd
import pandas as pd
#pathin = '/Users/ethan/Documents/GitHub/ethanweed.github.io/python-tutorials/data/'
#file = 'nettle_1998.csv'
#cd(pathin)
url = 'https://raw.githubusercontent.com/ethanweed/ethanweed.github.io/master/python-tutorials/data/nettle_1998.csv'
df = pd.read_csv(url, sep = ';')
# make a pandas "dataframe" from the .csv file. The file uses semicolons to separate the columns.
#df = pd.read_csv(file, sep = ';')
# Nettle reports the population data in 1000's, probably to save room in the data table,
#but that is an unusual number to think about population in, so let's convert to millions.
#While we're at it, let's convert km2 to millions, so that the number doesn't appear in scientific notation
#on the x-axis
df['Population'] = df['Population']*1000/1000000
df['Area'] = df['Area']/1000000
# look at the first lines of the dataframe
df.head()
Plotting Correlations¶
We can use seaborn to see if there is any clear relationship between these variables.
Is there a relationship countries' area and their number of languages spoken?
We can use the
sns.regplotfunction to take a quick look.
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
sns.regplot(x = "Area", y = "Languages", data = df)

There does seem to be some sort of relationship here, but it is difficult to see on the plot. A few countries are outliers, and they are pushing all the other data down into the lower-left corner. By transforming the data to a logarithmic scale, we can stretch them out a bit, and make them easier to see. Let's add two more columns to the dataframe, with log-transformed versions of the Population and Area data:
df['Population_log'] = np.log(df['Population'])
df['Area_log'] = np.log(df['Area'])
df['Languages_log'] = np.log(df['Languages'])
df.tail()
Now the relationship is a little easier to see:
# Plot the log-transformed data
sns.regplot(x = "Area_log", y = "Languages_log", data = df)

import scipy.stats as stats
# create a tuple "res" containing r and p-value for Pearson's correlation
res = stats.pearsonr(df['Area'], df['Languages'])
# round of the output to 5 decimal places
print("r (correlation coefficient): ", round(res[0],5))
print("p-value: ", round(res[1],5))
The output tells us that there is a positive correlation between the number of languages and the area of the country. We can see this in the correlation coefficient (cor) which is 0.29. The correlation coefficient is a number between 1 and -1, with 1 indicating a perfect positive correlation, and -1 indicating a perfect negative correlation. The p-value of the correlation indicates how confident we can be in the fit of the model.
Correlation Matrix¶
Sometimes it can be useful to look at all the correlations between all of the variables in a dataset at once. This can be done with a correlation matrix. However, we should be careful about reading too much into a correlation matrix: it just tells us how much the variables correlate with each other. In order to be more rigorous about making predictions, we will need to build linear models.
print( df[['Languages','Area', 'Population', 'MGS']].corr())
Modelling a Relationship as a Linear Regression¶
In the plot above, we used a linear model to draw the line between the points. The straight line in the plot is a linear model, that minimizes the distance between the line and every individual point.
If we generate some random numbers to create white noise, then the line should be close to horizontal.
We can test this by generating some white noise data. Here we create a vector of 1000 random numbers between 0 and 100 plotted against 1000 other random numbers between 0 and 100:
from random import seed
from random import randint
seed(42)
x = []
y = []
for _ in range(1000):
xvalue = randint(0, 100)
yvalue = randint(0, 100)
x.append(xvalue)
y.append(yvalue)
df_random = pd.DataFrame(
{'x': x,
'y': y})
Then we can fit a linear regression model to the data:
sns.regplot(x = "x", y = "y", data = df_random).set_title('White Noise')

If we were in doubt, our correlation matrix shows us that there is very little correlation between these two vectors of random numbers:
res = stats.pearsonr(df_random['x'], df_random['y'])
print("R (correlation coefficient): ", round(res[0],5))
print("p-value: ", round(res[1],5))
If we want to go beyond simply observing the correlation and instead use our linear model to make predictions about new data that we have not yet seen, we need to get the equation for our model's line.
That will allow us to extend the line in either direction, and make predictions.
The equation of a line is $y=mx+y_0$, where $y_0$ is the point at which the line intercepts the y-axis.
This is sometimes also written as $y=mx+b$, or $y=ax+b$. These equations are all equivalant.
The important thing for our purposes is that they define the slope and intercept of a line which represents a linear model of the data.
Linear models are very useful, and they are all over the place in statistics. In the case of our random, white-noise data, because the slope is nearly equal to zero, the intercept of the model is a very close approximation of the mean of y:
sns.regplot(x = "x", y = "y", data = df_random).set_title('White Noise')

import statsmodels.formula.api as smf
print('Mean of y =', df_random['y'].mean())
mod = smf.ols(formula = 'y ~ x', data = df_random).fit()
mod.summary()
Modelling Number of Languages as a Linear Function of Area¶
When estimating a linear model, we need to specify a formula. In the formula below, the ~ means "predicted by", so the formula reads: "Languages predicted by Area". ols stands for "ordinary least squares", which is the method by which the algorithm estimates the equation of the line.
import statsmodels.formula.api as smf
mod1 = smf.ols(formula = 'Languages ~ Area', data = df).fit()
mod1.summary()
import statsmodels.formula.api as smf
mod1 = smf.ols(formula = 'Languages ~ Area', data = df).fit()
mod1.summary()
In the data table above, toward the middle, in the column called "coef", we see "Area". This is the regression coefficient, or $B$ (beta).
But Area isn't the only thing correlated with the number of languages.
Population size looks like it might also be a relevant factor:
fig, axs = plt.subplots(ncols=2, sharey = True)
sns.regplot(x = "Area_log", y = "Languages_log", data = df, ax=axs[0])
sns.regplot(x = "Population_log", y = "Languages_log", data = df, ax=axs[1])

Multiple Regression¶
By adding Population as a second predictor variable, we can estimate the relative importance of both Area and Population in predicting the Number of Languages:
mod2 = smf.ols(formula = 'Languages ~ Area + Population', data = df).fit()
mod2.summary()
Now we can compare the $B$ values for Area and Population.
We see that Area has a stronger relationship with Language than Population.
On the other hand, with the introduction of the second predictor variable, Area is no longer a significant predictor.
Finally, the two together can better account for the variance in the data (adjusted $R^2$ = 0.17) than Area alone (adjusted $R^2$ = 0.072).
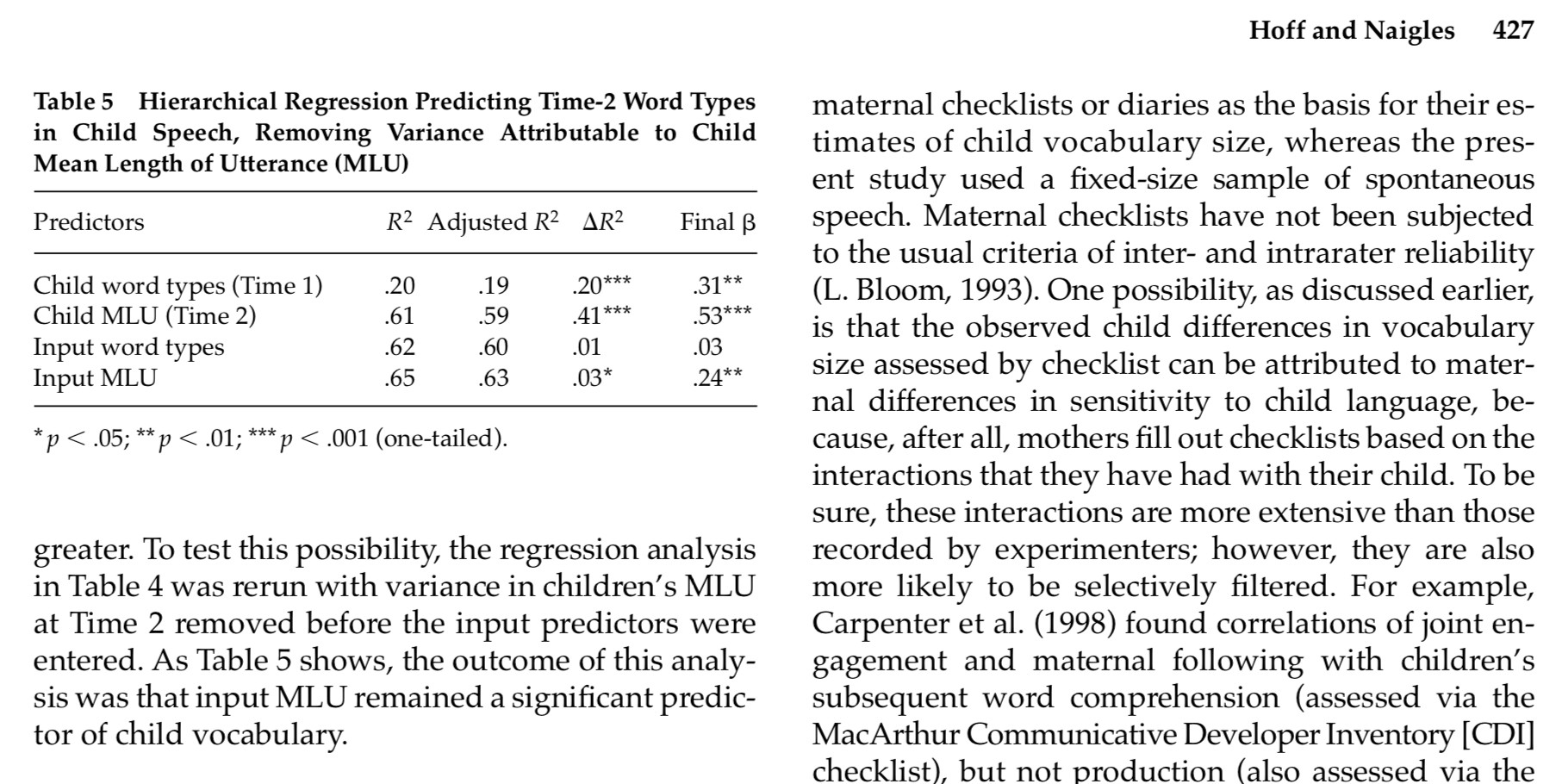
Now we can interpret the relative predictive strength of Input MLU in the data from Hoff & Naigles (2002)¶